Linux性能调优
一直以来都比较希望掌握在复杂系统中定位和分析问题的能力,所以也是承接上一片网络分析的文章,这篇文章中主要想试着尝试对程序运行过程中的问题进行分析和定位。
关于这个领域也是第一次接触,质量有限,之后再做增补。
性能优化领域的大牛 Brendan Gregg 对性能优化有个非常好的总结,这张图里包括了系统结构中各个部分在调试检测(Observability)过程中需要用到的工具。在他的博客中和这个 slide 中,更是提到了 Linux 系统中用于监测(Observability)、基准测试(Benchmarking)、调优(tuning)以及静态测试的工具。
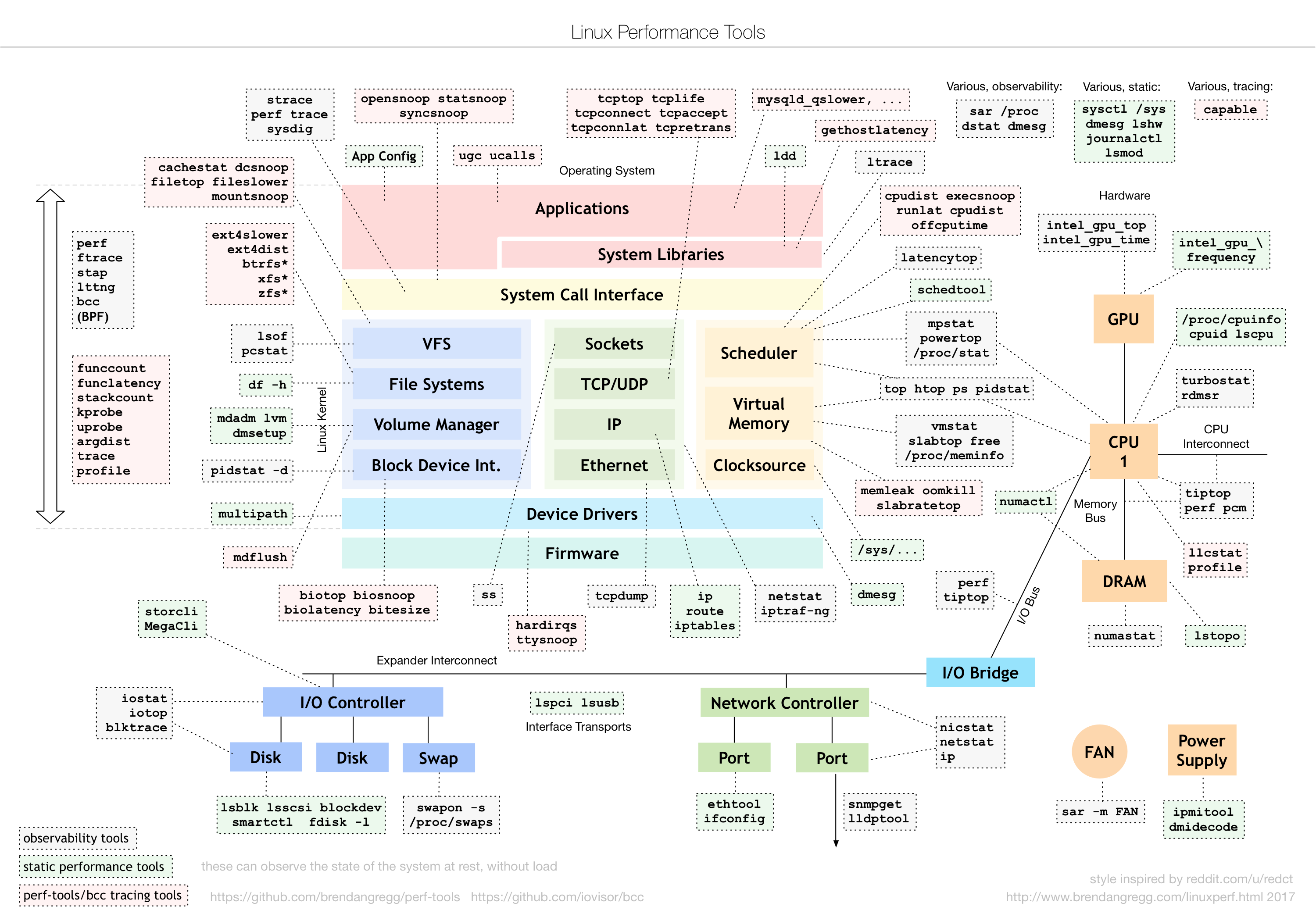{kind=link}
Perf
Perf (Performance Event) 在 Brendan Gregg 的归纳图中,属于性能监测工具,通常用于对程序中函数调用进行分析,与 GDB 相比,perf 通过 tick 中断进行采样,但是并不会中断程序运行,。
Perf 作为 Linux 系统内建的性能分析工具 (内核版本 2.6.31 以上),以性能事件采样作为基础,可取样的事件非常多,包括分析 Hardware event,比如 cpu-cycles、instructions、cache-misses、branch-misses 等,同样的也可以分析一些 Software event,比如 page-faults、context-switches 等。
perf 这种动态追踪工具,会给系统带来一定的性能损失。vmstat、pidstat 这些直接读取 proc 文件系统来获取指标的工具,则不会带来性能损失。
安装
两种方法:
一、可以直接从内核源码中进行编译安装
2
3
4
5
6
7
8
9
10
11
12
13
$ mkdir ~/install
$ cd ~/install
# 如果下述命令没有效果,
# 取消 /etc/apt/sources.list 中 deb-src 的注释
# 或者直接从 packages.ubuntu.com 下载内核源码
$ apt-get source linux-tools-`uname -r`
$ sudo apt-get build-dep linux-tools-`uname -r`
$ cd linux-`uname -r | sed 's/-.*//'`/tools/perf
$ make
# now you should see the new "perf" executable here
$ ./perf为了方便使用,可以将编译生成的 perf 执行文件加入到
/usr/bin目录中,或者
二、包管理工具安装
1 | # Ubuntu |
如果出现了一些警告,提示确实一些内核工具,只需按照提示安装即可,如果不放心的话可以用 $uname -r 确认版本号
###常用
一种用法是 perf top ,类似于 top ,能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用命令后可以看到:
1 | $ perf top |
解释:
Samples 采样数,event 事件类型、Event count 事件总数;
Overhead :性能事件在所有采样中的比例,用百分比表示,需要注意的是,如果采样数比较少,那下面的排序和百分比就没有什么实际参考价值;
Shared :函数或指令所在的动态共享对象 (Dynamic Shared Object) ,如内核、进程名、动态链接库名、内核模块名等;
Object :动态共享对象的类型,比如 [.] 表示拥护空间的可执行程序或动态链接库,[k] 表示内核空间;
Symbol :符号名,也就是函数名。有时会看到十六进制的地址表示函数位置。
另一种比较常用到的是 perf record ,虽然 perf top 可以实时的展示系统的性能信息,但并不能保存数据,因此就无法用于离线或者后续的分析。我们可以通过 perf record 保存数据,并用 perf report 展示数据。
1 | $ perf record |
相关参数
perf 命令参数很多,这里只列举其中的一部分,更多参见 https://perf.wiki.kernel.org/index.php/Tutorial#Events
Commands
1 | perf |
每个指令后都可以加 -h 参数来查看具体的使用方法。
依赖问题
在使用 perf 进行程序分析的时候,有时我们会看到函数名为十六进制内存地址,行末警告依赖缺失的问题:
1 | $ perf top -g -p 26606 |
可以看到,上述示例中,内核态的函数调用显示正常,而用户态的函数只能看到地址,这一般是由于 perf 找不到待分析进程依赖的库。
同样的问题,在分析 Docker 应用时更为显著。由于 Docker 容器应用本身就是一个特殊的进程,通过 Linux Namespace 进行了隔离,所以从外部我们是无法获取到进程的依赖库的。
那么如何解决这个问题呢?
你可能很容易就会想到,在主机中把相同的依赖库加上,但是这不管从操作复杂度还是从主机安全的角度上考虑,都是不太可行的。
另一个想法,在容器内部运行 perf,但需要注意的是,perf 的运行依赖于内核态,这要求容器处于特权模式下,然而一般情况下,出于安全考虑,我们会尽量避免构建特权容器(即容器进程拥有宿主机 root 的操作权限)。
比较好的做法是指定符号路径为容器文件系统的路径,可以执行:
1 | $ mkdir /tmp/foo |
bindfs 工具需要额外安装,这里它的作用是将容器的文件系统挂载到 /tmp/foo 路径下 (类似 mount –bind) 的功能,可以在 GitHub 下载源码进行安装。
更简单的方法是,*在容器内部 report *。可以利用 record 指令记录分析结果,并将其传到容器中,再使用 report 进行显示并分析。
1 | # 将获取的文件复制到容器中 |
这里两点需要注意。
- perf 工具的版本问题。在最后一步中,我们运行的工具是容器内部安装的版本 perf_4.9,而不是普通的 perf 命令。这是因为, perf 命令实际上是一个软连接,会跟内核的版本进行匹配,但镜像里安装的 perf 版本跟虚拟机的内核版本有可能并不一致。
- 注意镜像是基于什么系统的,对于不同的发行版安装 perf 的方式不同。
Strace
前面已经提到了,进程在调用内核态的能力 (如访问硬件设备) 的时候必须要要间接通过系统调用完成,strace 工具就可以用来跟踪进程执行时的系统调用和所接收的信号。
常用
跟踪可执行程序及其所有子进程:
1 | # -f -F 启用跟踪 fork 和 vfork 的子进程 |
跟踪服务程序:
1 | $ strace -o output.txt -T -tt -e trace=all -p 28989 |
跟踪 PID 为 28989 的进程所有的系统调用 (-e trace=all) ,并统计系统调用花费的时间 (-T) ,以及开始的时间,以可视化的时分秒格式显示 (-tt),并记录在 output.txt 文件中。
参数
| Args | Description |
|---|---|
| -c | 统计每一系统调用的所执行的时间,次数和出错的次数等. |
| -d | 输出 strace 关于标准错误的调试信息. |
| -f | 跟踪由 fork 调用所产生的子进程. |
| -ff | 如果提供 -o filename ,则所有进程的跟踪结果输出到相应的 filename . pid 中, pid 是各进程的进程号. |
| -F | 尝试跟踪 vfork 调用.在 -f 时, vfork 不被跟踪. |
| -h | 输出简要的帮助信息. |
| -i | 输出系统调用的入口指针. |
| -q | 禁止输出关于脱离的消息. |
| -r | 打印出相对时间关于,,每一个系统调用. |
| -t | 在输出中的每一行前加上时间信息. |
| -tt | 在输出中的每一行前加上时间信息,微秒级. |
| -ttt | 微秒级输出,以秒了表示时间. |
| -T | 显示每一调用所耗的时间. |
| -v | 输出所有的系统调用.一些调用关于环境变量,状态,输入输出等调用由于使用频繁,默认不输出. |
| -V | 输出 strace 的版本信息. |
| -x | 以十六进制形式输出非标准字符串 |
| -xx | 所有字符串以十六进制形式输出. |
| -a column | 设置返回值的输出位置.默认为40. |
| -e trace=set | 只跟踪指定的系统 调用.例如: -e trace=open, close , rean, write 表示只跟踪这四个系统调用.默认的为 set=all. |
| -e trace=file | 只跟踪有关文件操作的系统调用. |
| -e trace=process | 只跟踪有关进程控制的系统调用. |
| -e trace=network | 跟踪与网络有关的所有系统调用. |
| -e strace=signal | 跟踪所有与系统信号有关的 系统调用 |
| -e trace=ipc | 跟踪所有与进程通讯有关的系统调用 |
| -e abbrev=set | 设定 strace输出的系统调用的结果集. -v 等与 abbrev=none.默认为 abbrev=all. |
| -e raw=set | 将指 定的系统调用的参数以十六进制显示. |
| -e signal=set | 指定跟踪的系统信号.默认为all.如 signal=!SIGIO (或者 signal=!io ),表示不跟踪 SIGIO 信号. |
| -e read=set | 输出从指定文件中读出 的数据.例如: -e read=3,5 -e write=set输出写入到指定文件中的数据. |
| -o filename | 将 strace 的输出写入文件 filename |
| -p pid | 跟踪指定的进程 pid. |
| -s strsize | 指定输出的字符串的最大长度.默认为 32.文件名一直全部输出. |
| -u username | 以 username 的 UID 和 GID 执行被跟踪的命令 |
总结
当然了,性能调优是一个很大的命题,性能问题的症结可能出现在任何一个地方,如 CPU 中频繁的上下文切换造成的大量开销、调度失败重试造成的系统负担、大量网络包引发频繁的数据接收引起的软中断等。
面对这些问题,一个是靠对底层系统的全面理解,另一个是依靠对各种工具的灵活使用,才能形成一套完整且有效的方法论,快速定位问题,完成性能优化。
我更愿意称这项能力为一种“内功”,大部分时候,我们会更注重对“招式”的学习,而到了“招式”本身已经无法解决问题的时候,内功就显得尤为重要了。
参考
- Linux 性能优化实战, 倪朋飞, geekban.org
- Linux kernel profilling with perf, https://perf.wiki.kernel.org/index.php/Tutorial#Events
- Linux 效能分析工具: Perf, http://wiki.csie.ncku.edu.tw/embedded/perf-tutorial
- Linux Tools Quick Tutorial, https://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/strace.html