[Golang] 容器
当然了,这里的容器不是CNI之类的运行容器,而是指Golang中存储和组织数据的方式。
当然了,这里的容器不是CNI之类的运行容器,而是指Golang中存储和组织数据的方式。
Go语言中的函数特性:
此篇文章转载legendtkl的博客终端10X工作法,我一直很喜欢terminal使用中带来的一些小tricks,这篇文章刚好列举了一些代表性的,之后我会在这篇文章的基础上,将我比较常用的记录并放到顶部,也算是方便查找。
另外也非常感谢legendtkl的文章合抱之木,生于毫末,也算是我开始写博客的原因之一。
以下为正文内容。
使用 Kubeadm 工具在集群上安装 Kubernetes.
UPDATE 2020/05/15:
Troubleshooting for kubeadm.
cat /etc/timezonetimedatectl1 | root@openstack1:~/kubernetes# timedatectl |
If you haven’t sychronized with internet, the value of System clock synchronize must be no
Use sudo systemctl restart systemd-timesyncd.service to activate timesyncd
1 | root@openstack1:~/kubernetes# systemctl status systemd-timesyncd.service |
sudo timedatectl set-ntp true
timedatectl list-timezones to check all the time-zones.
sudo timedatectl set-timezone Asia/Shanghai
Using command line
1 | installation |
This is a copycat of Comprehensive data explorationi with Python. Since I had limited time to accomplish AI project. So I preferred learn from other’s notebook. And ‘Comprehensive data explorationi with Python’ is apparently the most fit one for me.
According to the article, the first thing we should do is look through the whole data set, and find the most important variables which matters when you buy a house.
And then an important problem we must deal with is Data Cleaning.
While ‘Type’ and ‘Segment’ is just for possible future reference, the column ‘Expectation’ is important because it will help us develop a ‘sixth sense’. To fill this column, we should read the description of all the variables and, one by one, ask ourselves:
I went through this process and concluded that the following variables can play an important role in this problem:
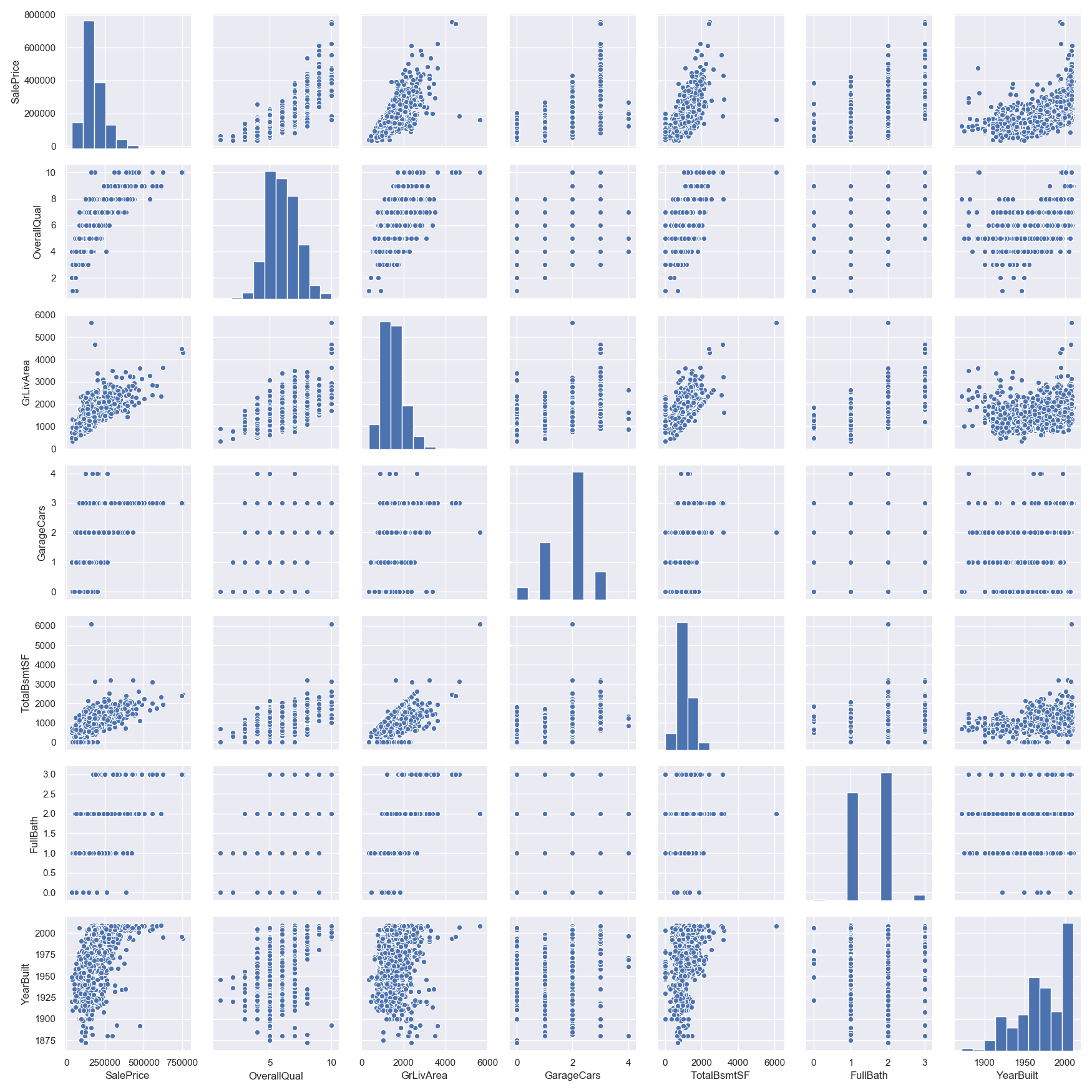
Hmmm… It seems that ‘SalePrice’ and ‘GrLivArea’ are really old friends, with a *linear relationship.***
In my opinion, this heatmap is the best way to get a quick overview of our ‘plasma soup’ and its relationships. (Thank you @seaborn!)
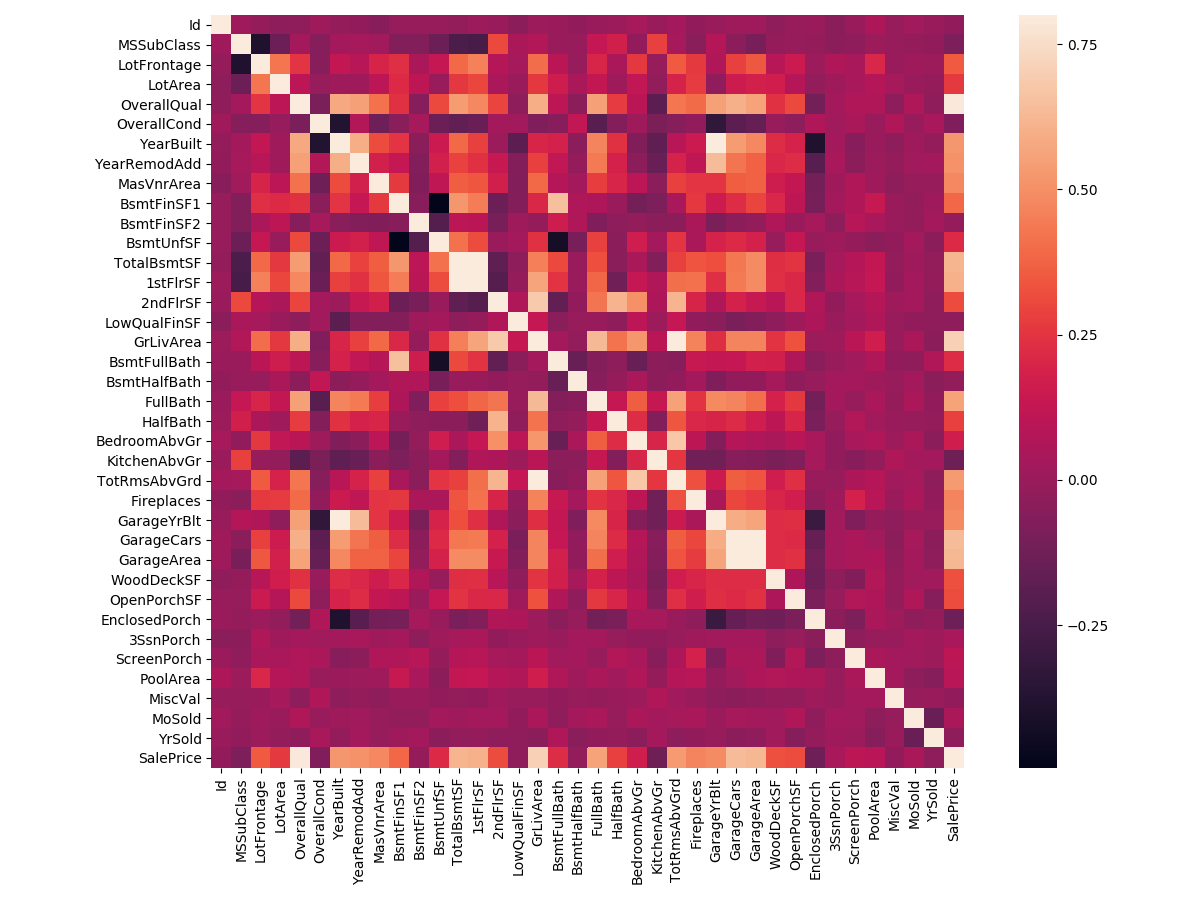
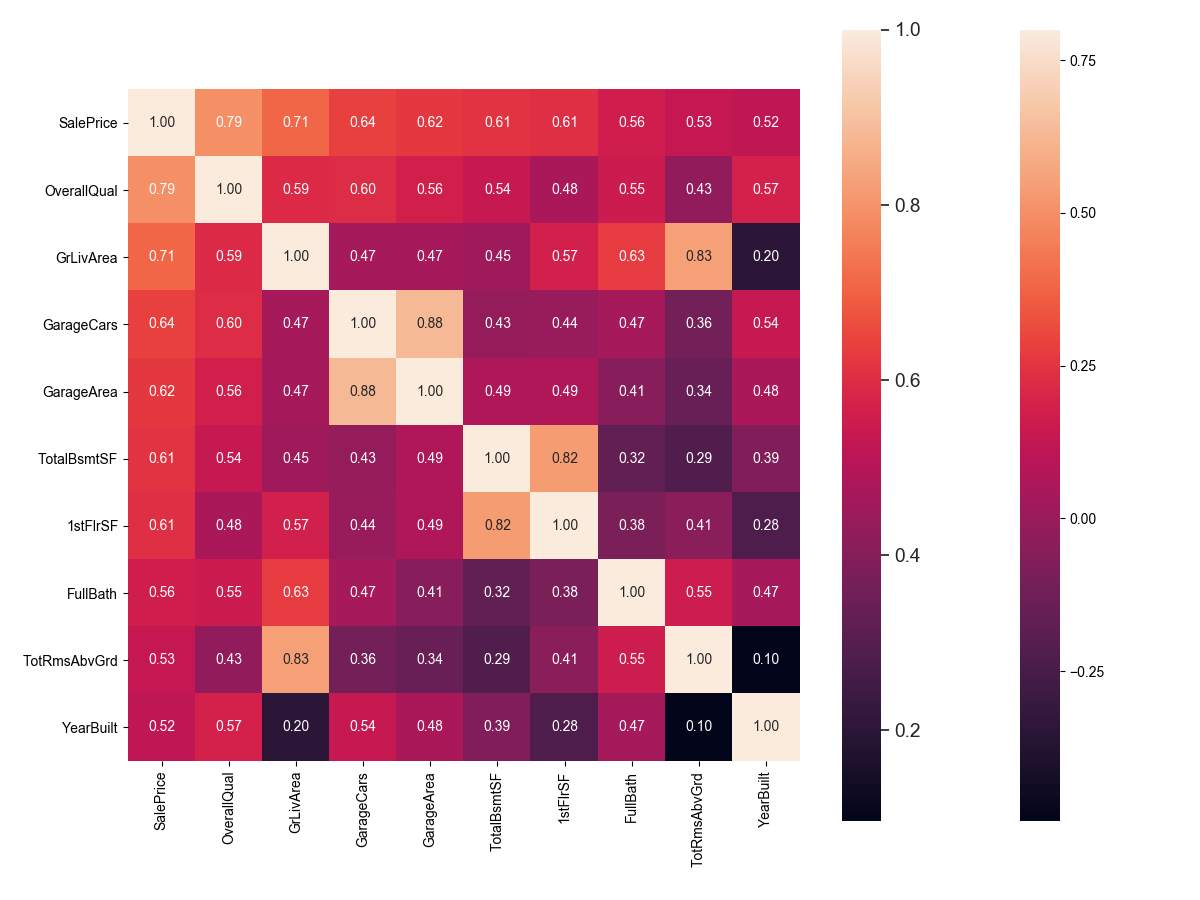
According to our crystal ball, these are the variables most correlated with ‘SalePrice’. My thoughts on this:
Let’s proceed to the scatter plots.
Using script below, we can easily get the missing data.
1 | #missing data |
| Total | Percent | |
|---|---|---|
| PoolQC | 1453 | 0.995205 |
| MiscFeature | 1406 | 0.963014 |
| Alley | 1369 | 0.937671 |
| Fence | 1179 | 0.807534 |
| FireplaceQu | 690 | 0.472603 |
| LotFrontage | 259 | 0.177397 |
| GarageCond | 81 | 0.055479 |
| GarageType | 81 | 0.055479 |
| GarageYrBlt | 81 | 0.055479 |
| GarageFinish | 81 | 0.055479 |
| GarageQual | 81 | 0.055479 |
| BsmtExposure | 38 | 0.026027 |
| BsmtFinType2 | 38 | 0.026027 |
| BsmtFinType1 | 37 | 0.025342 |
| BsmtCond | 37 | 0.025342 |
| BsmtQual | 37 | 0.025342 |
| MasVnrArea | 8 | 0.005479 |
| MasVnrType | 8 | 0.005479 |
| Electrical | 1 | 0.000685 |
| Utilities | 0 | 0.000000 |
So how to handle the missing data?
We’ll consider that when more than 15% of the data is missing, we should delete the corresponding variable and pretend it never existed. So we delete ‘PoolQC’, ‘MiscFeature’, ‘Alley’, ‘Fence’, ‘FireplaceQu’ and ‘LotFrontage’.
As for ‘GarageX’, they all have the same number of missing data. Maybe the missing data refers to the same set of observations. Since the most important information regarding garages is expressed by ‘GarageCars’ and considering that we are just talking about 5% of missing data, I’ll delete the mentioned ‘GarageX‘ variables. The same logic applies to ‘BsmtX‘ variables.
As for ‘MasVnrArea’(砖石饰面面积) and ‘MasVnrType’(砖石饰面种类), we can consider that these variables have a strong correlation with ‘YearBuilt’ and ‘OverallQual’ which are already considered. So we delete ‘MasVnrArea’ and ‘MasVnrType’.
We’ll delete all the variables with missing data, except the variable ‘Electrical’. In ‘Electrical’ we’ll just delete the observation with missing data.
1 | #dealing with missing data |
If the output is ‘0’, it means you have fully delete missing data.
The primary concern here is to establish a threshold that defines an observation as an outlier. To do so, we’ll standardize the data. In this context, data standardization means converting data values to have mean of 0 and a standard deviation of 1.
1 | 这里主要关注的是建立一个将观察值定义为异常值的阈值。为此,我们将对数据进行标准化。在这种情况下,数据标准化意味着将数据值转换为平均值为0且标准差为1。 |
1 | #standardizing data |
这一步的目的应该是为了找出数据中的离群值,这里需要关注的是两个大于7的变量。
1 | #bivariate analysis saleprice/grlivarea |
将’GrlivArea’中的离群值删除。
之后考察’TotalBsmtSF’中的离群值,但它的离群值表现在可以接受的范围之内。
According to Hair et al. (2013), four assumptions should be tested:
The point here is to test ‘SalePrice’ in a very lean way. We’ll do this paying attention to:
1 | #histogram and normal probability plot |
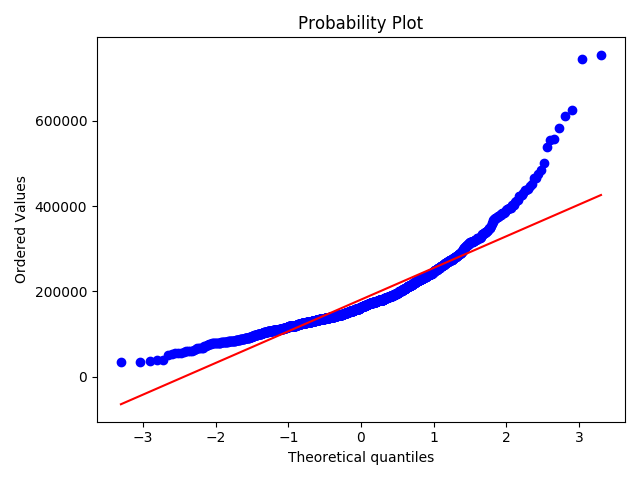
对变量取log转换得:
1 | #applying log transformation |
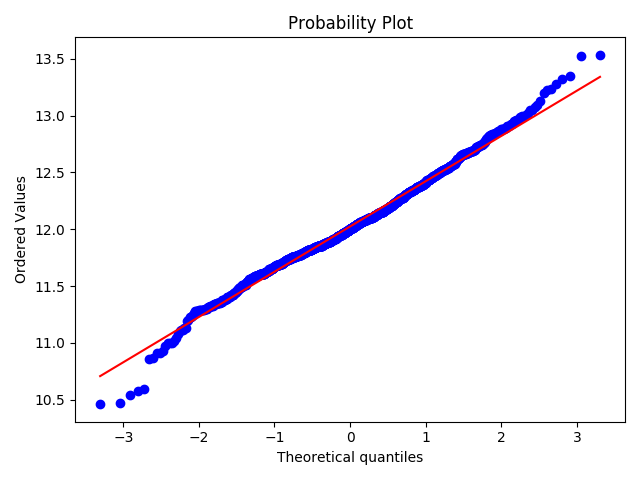
可以看到,散点更为均匀地分布在了直线的两侧。
以同样的方法对’GrLivArea’与’TotalBsmtSF’进行处理。
其中面临一个很严重的问题是,有些值为0,所以在这些值上,我们无法对它们取log。要在此处应用对数转换,我们将创建一个变量,该变量可以具有或不具有地下室的效果(二进制变量)。然后,我们将对所有非零观测值进行对数转换,而忽略那些值为零的观测值。这样,我们可以转换数据,而不会失去某些变量的影响。
1 | #create column for new variable (one is enough because it's a binary categorical feature) |
| Variable | Segment | Data Type | Comments |
|---|---|---|---|
| GrLivArea | 1 | 0 | 生活面积 |
| TotalBsmtSF | 1 | 0 | 地下室总面积 |
| GarageArea/GarageCars | 1 | 0 | 车库 |
| YearBuilt | 0 | 1 | 建造年份 |
| CentralAir | 0 | 1 | 中央空调 |
| OverallQual | 0 | 1 | 总体评价 |
| Neighborhood | 2 | 1 | 地段 |
Now we can make sure there 7 variables will participate in our model. And we have cleaned the data set. The final thing left to do is to get the PREDICTION.
Why use this? Idk, otherwise the blog didn’t describe the reason clearly.
The code displays below. And I have little trouble understanding the Random Forest Algorithm.
1 | # 获取数据 |
@hou说了许久,刚好上次申请的证书快过期了,这次把泛域名开启HTTPS的一些流程及注意事项记录一下。
UPDATE 2020/06/15
certbot 太难用了,说是自动更新,每次都不 work,换用 acme.sh 。
要实现:
usreadd -Gpasswd --stdin USERNAME,在脚本中可以使用echo "PASSWORD" | passwd --stdin USERNAME,但在Ubuntu中passwd并不支持--stdin,此时可以使用echo USERNAME:PASSWORD | chpasswd/etc/sudoers中chage1 | !/bin/bash |
遇到的问题:
while循环只执行一次,后添加了-n参数
新建用户修改权限失败passwd: Authentication token manipulation error
passwd: password unchanged,这是由于有权限改/etc/passwd而无权限修改/etc/shadow
未解决:使用chage修改用户有效时间,以此达到让用户登陆账户立即强制改密码存在问题,改密码无效,可能是权限问题。
谈到区块链技术,有个绕不过的东西,那就是比特币。比特币被称为“分布式的账单”,这是区别于银行而言的。传统货币中是有银行这个中心存在的,银行通过印发钞票、增减债券、修改准备金等金融手段调控货币,使其稳定。银行作为一个受信任的第三方,保有交易双方的交易信息,也就是其账本。
而中本聪提出比特币白皮书的提出是有一个背景的,那就是08年的金融危机,金融危机后来被认为是银行、评级机构对信用的滥用导致的。这也引发了人们的担忧:当有一天,银行变得“不靠谱”的时候,我们手上的货币还能靠谱吗?